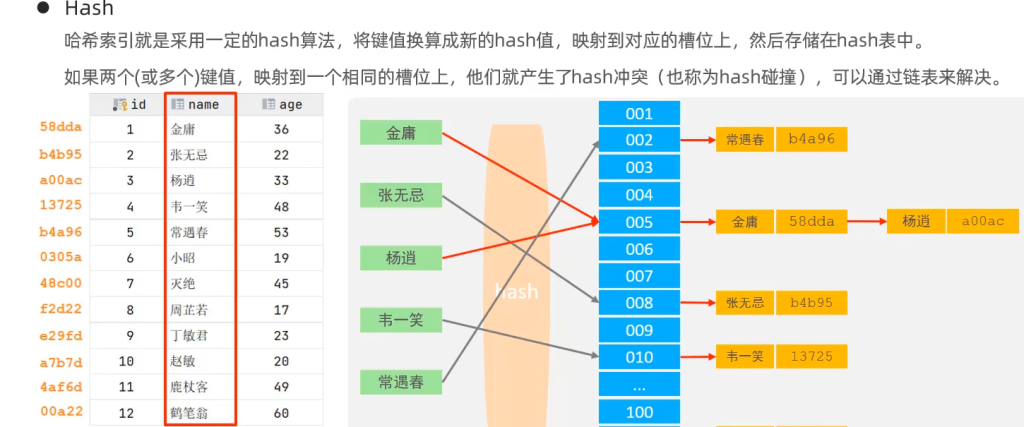
B-Tree:
例如5阶的B树:
最大指针为5,最大Key为4 (n-1) (Key即索引),Key指向数据(或其指针).
每当有新的索引试图插入B-Tree,就会与当前节点现存的索引作大小比较:
然后找到合适的区间,区间有一个指针指向子节点,最后插入被指向的节点(重复上述过程),最后新索引插入在叶子节点
这样就完成了索引的B-Tree结构.
当叶子节点的Key(索引)数量到达上限时,新索引插入之后,中间索引向上分裂,原节点从中间分家,成为两个新的节点
以此类推……….
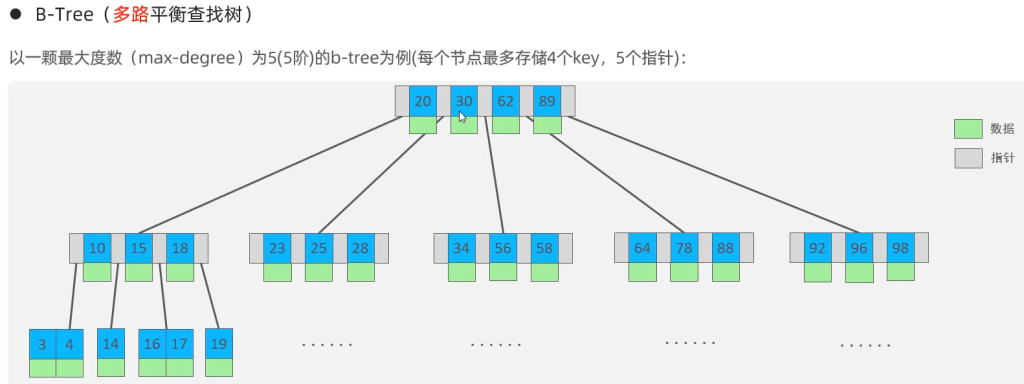
B+ -Tree
例如:3阶的B+树
底层原理与B树相同,最大的区别是:
当节点存储的索引超过上限分家时,将中间的索引留在当前节点中,再复制一份中间索引向上分裂出去,并且形成一个单向的链表指向下一个叶子节点.
所以叶子节点包含了所有节点的索引.在InoDB中增强了算法,将所有叶子节点的链表连接由单向改为双向,便于范围查询和反向遍历
最大的优点:
所有数据都在叶子节点中,搜索效率稳定.其他父节点不存储数据,仅起到区间分类的作用,并且节省内存空间.
tips:每个节点(每页)大小16KB,存储数据会导致可存储的索引数量下降,进而让树变高
支持双向链表,便于范围搜索和排序
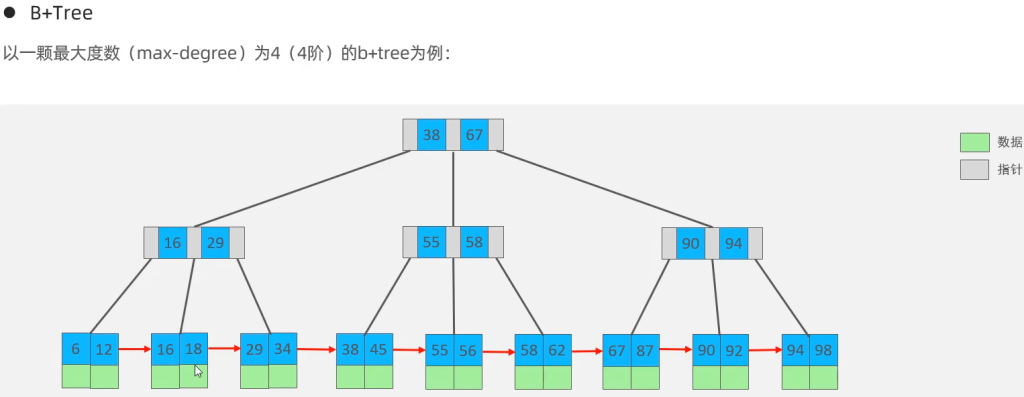
Hash结构
计算数据库表中的每一行级的Hash值,再将数据通过特定的哈希函数计算出数据对应的Hash槽位,
然后将Hash值填入对应槽位.
当两个Hash值相同时(哈希冲突),就会把两个数据链成链表.
Hash结构不支持范围查找,仅支持根据Hash值的精确查找